
基本用法
more file.txt
less
和more很像,但是可以上下翻动,感觉less和more只需要less就可以了,完全可以去掉more啊
基本用法
less file.txt
grep
这个是我非常常用的一个命令了,尤其是在问题排查的时候,需要用grep从大量的数据中筛选出一些我想要的。 grep也支持正则表达式匹配。
基本用法
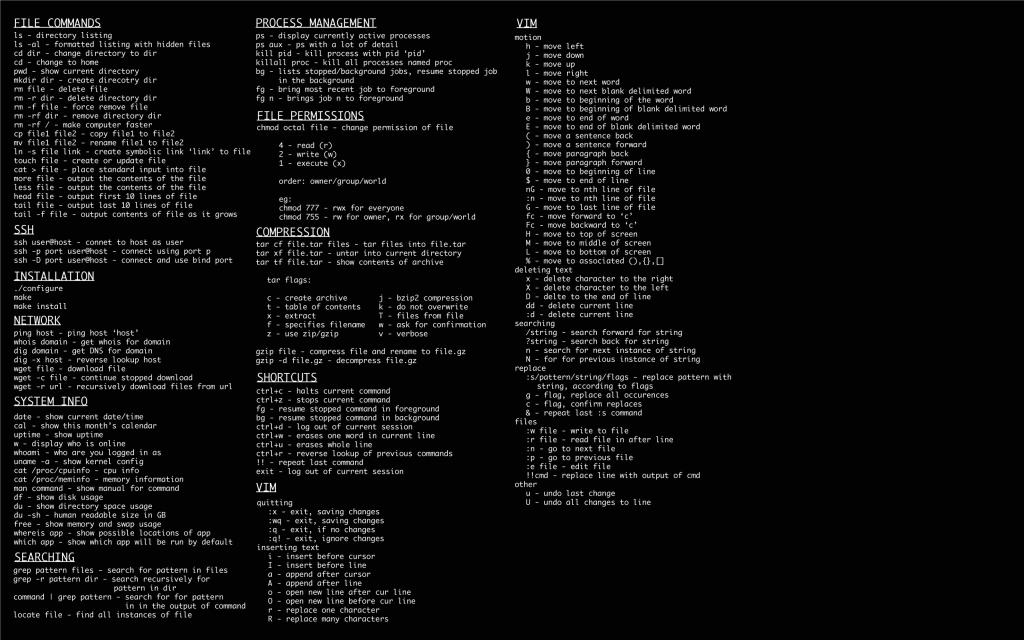
grep "abc" file 从file中筛选出包含 abc的行。
awk
开头我也说过,这个命令是我最常用的命令之一,比如在文件有多列的时候,我可以用awk输出具体某几列,或者做一些简单的统计 求和,求平均值啊,再或者做一下简单的数据格式化。
基本用法
do{partsize=`df -m | grep $youkuhome/mnt/$p | awk '{print $2 }'`[ ${partsize} -gt 500 ] && {_log "mount data, partsize=${partsize}"#mkdir -p $youkuhome/var/ikuacc/data/data${cnt}ln -sfn $youkuhome/mnt/$p $youkuhome/var/ikuacc/data/data${cnt}cnt=$((${cnt}+1))}}。$ cat /usr/local/class/logs/access.log | awk '{print $4,$7,$nf}' | awk -f '"' '{print $1,$2,$3}' | sort -k3 -rn | head -10。awk数组中还可以使用字符串下标,其实,不管你使用的下标是字符串还是数字,awk在幕后还将其认为是字符串下标。
do{partsize=`df -m | grep $youkuhome/mnt/$p | awk '{print $2 }'`[ ${partsize} -gt 500 ] && {_log "mount data, partsize=${partsize}"#mkdir -p $youkuhome/var/ikuacc/data/data${cnt}ln -sfn $youkuhome/mnt/$p $youkuhome/var/ikuacc/data/data${cnt}cnt=$((${cnt}+1))}}。$ cat /usr/local/class/logs/access.log | awk '{print $4,$7,$nf}' | awk -f '"' '{print $1,$2,$3}' | sort -k3 -rn | head -10。awk 'begin {print "begin: " var} {print "process: " var} end {print "end: " var }' a var=1 。
cat data | awk -F'\t' '{print $1,$3}' 把每行数据按tab分列,并输出1 3列
参考资料
阮一峰 awk介绍

sort
对标准内容做排序,
基本用法
支持无序字典按字符顺序排序、顺序字典随机乱序以及倒(逆)序重组字典。动力一号排序(用于热度指数排列)指标说明:数值越高代表越多人参与此股票.在飞狐软件里面的股票排列里按f6键,选出动力一号排序的指标位置,点确定.再到动力一号排序一列点右键刷新指标就出来了hsl:=vol/capital*100。按【上方向】键,进入“设置列表”栏→按【左,右方向】键选择需要更改的参数→按【确定】键选中,按【上,下方向】键调整到所需的参数值→按【确定】键退出调整的参数值(如需改动其他参数,则按以上方法改动即可)→按【下方向】键,切换到设置功能选择栏→按【左,右方向】键选择【保存】→按【确定】键即可保存所更改的内容(注意:不保存就返回linux命令,则所更改的内容失效)→选中【返回】→按【确定】键即可退出设置操作,返回到主界面。
