
这种形式将前面管道前命令输出的结果作为getline的输入,每次读取一行。这里>的意思,是把前面命令得到的东西放到后面所给的地方,>>的作用linux命令,和>的相同,区别是把结果追加到前一行得出的结果的后面,具体的说是下一行,而前面一行命令得出的结果将保留,这样可以使这个a.txt文件越来越大(想到如何搞破坏了。同时,标有树木的方格表示这里是花园,地下不能埋设管道.下图表示一个4*5的地区, 4,2 处有一个花园. 有三种不同的铺设方法,如图: 下面请你写一个程序,对一个给定的地图,找出有多少种不同的铺设方案.【输入文件】 输入文件trase.in的第一行为两个整数n和 m 都不超过10 ,接下来的m行,每行有n个整数,表示地图中的每一小格.其中1-4依次表示图中四种管道,5表示花园,0表示空地.【输出文件】 输出文件trase.out输出一个整数,表示不同方法数.【样例输入】4 50 0 3 20 4 0 54 0 0 04 0 1 00 3 0 0【样例输出】3jsoi2013春季函授1932145图11234图31245图2123456781234卒axyp1 p2 p3 p4 p5 p6 p7 p8 c 马 b(4,8)。
1、管道命令会自动忽略错误的标准输入
2、管道命令后面接的命令必须能够接收标准输入,不能接收的命令包括ls、cp、mv等
管道需要搭配其他命令来使用,下面来几个例子。
1、查看tomcat进程详情(常用,管道入门级)
ps%20-ef%20|%20grep%20tomcat
ps命令用于报告当前系统进程状态linux命令,-e参数表示显示所有用户所有进程,-f参数表示全格式显示,ps%20-ef的输出如下图:
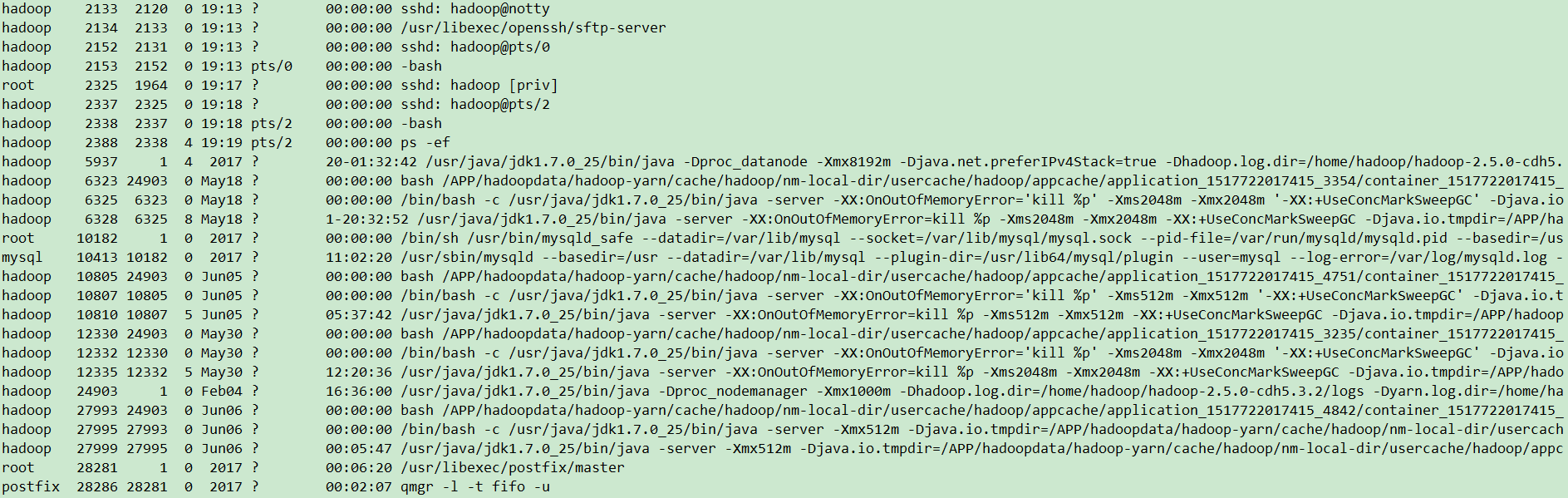
这一条条的结果,通过管道,输入给后面的命令。
grep全称是Globally%20search%20a%20Regular%20Expression%20and%20Print,能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。所以用管道连接后,这个命令就表示显示所有进程,并且格式化输出,然后用“tomcat”字符串来过滤每一行,得到最终的输出结果。
2、查看物理cpu个数(进阶级,多管道连用)
拆解:
cat%20/proc/cpuinfo:查看cpu详细信息
grep%20"physical%20id":用“physical%20id”过滤每一行
sort:将输入结果按照ASCII值进行排序
uniq:去重
wc -l:计算行数
我们从sort开始看:

你要问我问啥输出这么多重复的,你自己敲一下cat%20/proc/cpuinfo就明白了。
3、用管道计算1+2+3+……+100(奇技淫巧版)
看到这道题,你会想怎么去做?写个循环i++%20j++?还是用公式(1+100)*n/2?
我们的bash可以非常巧妙的解决这个问题。
首先我们要知道linux 中有个计算器,叫bc,我们先来看看他的用法。
直接输入bc进入程序

扔给bc一条算式
看到第二种用法,我们或许就意识到了,bc可以直接计算输入给他的字符串!
是不是很有趣?
那我们能不能拿到一个1+2+3+..+99+100的字符串呢?
我们知道echo {1..100}可以生成1 2 3 4 5 … 100的字符串,中间以空格隔开。

等等..用空格隔开?把空格换成加号不就行了么?我们来:
Echo {1..100} |tr ' ' '+'看我们拿到了什么?
再来Echo {1..100} |tr ' ' '+'|bc

看看~是不是很厉害呢?
管道符是linux 中重要的符号,真的是很棒的发明~
